Migrer vers le Cloud, ce n’est pas déplacer des serveurs : c’est transformer la Production. Nouveaux risques, nouveaux réflexes, nouvelle organisation.

Nous sommes vendredi soir, comme chaque mois Camille, CTO,se rend au COMEX de sa société. L’ambiance est détendue, le week-end approche. La réunion démarre et le directeur prend la parole.
Etrange, on commence par un sujet IT. Camille retourne l’écran de son téléphone portable contre la table pour écouter plus attentivement. « A la suite des nombreuses remarques de Camille sur la mauvaise qualité de l’infrastructure qui semble responsable de tous nos incidents, et vu les coûts prohibitifs que cela représente, j’ai décidé de ne pas renouveler le contrat avec notre infogérant. Camille, on compte sur toi pour migrer tout ça sur le Cloud ! Tu as 2 ans car de toute façon ils vont fermer le data center qui est devenu obsolète ».
« C’est tout ce dont j’avais besoin, un projet comme celui-là avec tous les ennuis qu’on a déjà. En même temps, comme la plupart des projets, ça va décaler, voir même être annulé quand ils réaliseront ce que ça signifie vraiment… »
« Je n’ai même pas été consulté, j’aurais pu leur dire que c’était suicidaire (est-ce pour cela qu’on ne l’a pas contacté ? NDLR). On me demande de ne plus avoir un seul élément d’infra à nous, dans un délai de 2 ans, c’est vraiment dangereux… »
« Bon l’idée n’est peut-être pas totalement mauvaise, on peut mettre les nouveaux projets sur le Cloud et migrer le legacy en quelques années en montrant qu’on baisse les coûts, mais c’est certain que deux ans c’est irréaliste… »
« En réalité je n’ai aucune idée du nombre d’applications qu’on a sur ces serveurs, à quoi elles servent exactement, dans quelles technos… Et sans parler du Shadow IT, je suis sûr qu’on a des Métiers qui ont développés des outils directement connectés sur des bases de données sans nous le dire car ils nous jugeaient trop lents… »
« Bon on va en faire une opportunité, on va bien arriver à comprendre tout ça, le Cloud tout le monde y va donc ça ne doit pas être idiot, mais j’avoue je n’arrive même pas à concevoir ce que ça va réellement changer ''d’aller sur le Cloud'' ».
Vous venez de voir Camille passer à travers les 5 étapes du deuil de sa situation passée, celle qu’il adorait détester mais qui était néanmoins sa zone de confort. En fonction de votre tempérament de CTO et des difficultés que vous rencontrez dans votre vie ce cheminement peut prendre entre 5 minutes et 5 mois.
Tout va dépendre de votre approche avec le Cloud et des opportunités que vous souhaitez obtenir au-delà du fait que, comme Camille, on vous a peut-être forcé la main. Les avantages principaux sont :
Le patron de Camille a justifié la migration sur le Cloud avec un argument économique. C’est en réalité une question très complexe. Oui, vous pouvez éteindre ou diminuer votre utilisation des ressources quand vous ne les utilisez pas. Oui, vous pouvez créer un environnement pour quelques heures, le temps de tester une idée. Mais dans quelle mesure pouvez-vous réellement faire cela avec vos cas d’usage ? Etes-vous sûr que vous n’allez pas créer un effet rebond ? Quelle garantie avez-vous que le prix de votre abonnement Cloud ne va pas augmenter dans les prochains mois de façon que vous jugerez déraisonnable ?
Si vous faites de l’aspect économique votre première raison d’aller dans le Cloud je vous propose de réfléchir sérieusement à ces points. Oui, le Cloud peut faire baisser les factures, mais pas toujours, et le gain principal est surtout obtenu lors de la migration qui vous pousse à réaliser l’inventaire précis de votre infra… mais surtout de vos besoins.
Il est fort probable que la première chose que vous constatiez une fois que vous aurez annoncé votre volonté de migrer dans le Cloud soit la constitution de deux camps. Le premier, ceux qui ne voient pas trop l’intérêt, pensent perdre du contrôle, vont proposer une migration à minima en répliquant le SI actuel. Le second, en revanche, voudra en profiter pour tout refactorer, utiliser les dernières technos en affirmant que dans le cas contraire on va juste faire plus cher pour moins bien.
De ces deux camps va généralement émerger un premier débat, on migre en IaaS ou PaaS ? Le IaaS (pour Infra as a Service), vous en avez peut être déjà si vous utilisez de la virtualisation, VMWare ou autre. Rien ne change ou presque pour les équipes IT et les administrateurs infra, vous êtes en total contrôle de l’infrastructure, avec néanmoins un gain de temps énorme pour sa mise en place ! Le PaaS (pour Platform as a Service) a une ambition plus large, il est souvent associé à des technologies telles que Kubernetes, son idéal étant qu’on pousse du code et que cela soit tout de suite disponible aux utilisateurs. Mais cela nécessite une refonte plus ou moins profonde de votre code et de remplacer l’expertise infra par une expertise Cloud. Pour le SaaS (ou Software as a Service) c'est souvent le PaaS ou le IaaS d’une autre société !
Cet article n’a pas pour vocation de discuter des choix d’implémentation, je vous laisse décider de tout cela en fonction de votre stratégie, de votre budget, de votre legacy… Il y a de fortes chances que vous ayez à gérer IaaS et PaaS au bout du compte…
Mais ce qui est sûr, c’est que si vous quittez un infogérant (interne ou public) pour aller dans le Cloud, le changement le plus impactant pour vous sera que désormais personne d’autre que vous ne sera là pour gérer les incidents, parfois en astreinte, ni pour vous conseiller dans les évolutions techniques.
Pendant que Camille tente de se souvenir du chanteur de ces paroles, il devient évident qu’il va falloir décider qui a le droit d’administrer les éléments du Cloud. Une nouvelle fois, deux camps vont se former. Les partisans radicaux du « You Build It, You Run It » qui sont persuadés que le Cloud doit être donné aux développeurs, que chez eux ça marche en 5 minutes. Et les partisans du « No Right, No Fear » qui se disent que plus la surface est réduite moins le risque est grand d’avoir une catastrophe sur les plans techniques, sécurité ou financier ! A cela s’ajoutent de nouveaux risques de Shadow IT, avec le métier qui pourrait se payer sa propre souscription, beaucoup plus simple à cacher du CTO que le PC acheté à la Fnac et caché sous le bureau.
Tous les modèles de droits sont possibles en fonction de votre contexte. Si on reprend la situation de Camille cela se résume à :
Quoi qu’il arrive, surtout à l’échelle, il paraît indispensable de mettre en place un ensemble de « Trust &Control ». D’abord pour la sécurité, la cohérence de l’architecture technique et le suivi capacitaire de consommations des éléments du Cloud et de son impact financier.
Dans le cadre d’une migration IaaS, le Cloud s’avère surtout un facilitateur sur les activités de production en rapport avec l’infrastructure. La possibilité de créer et redimensionner les ressources en quasi-temps réel, d’obtenir du monitoring sur chaque ressource et de sécuriser davantage les accès est déjà une plus-value importante. Pouvoir lister l’intégralité des ressources dans un environnement qui était non cartographié, accélère considérablement la gestion de l’obsolescence, des risques IT & cyber, la continuité de service et le pilotage de la sous et surconsommation des ressources.
Dans le cadre d’une migration PaaS, les impacts vont être bien plus grands car cela impose une ambition bien supérieure en terme de qualité de service.
Il ne sera plus possible de faire l’impasse sur le fait d’avoir un pipepline de CI/CD, un processus de gestion de l’obsolescence (oui,les service du Cloud peuvent se déprécier à très grande vitesse), la qualité du monitoring, une application stable sans intervention système, un suivi capacitaire et budgétaire sur tous les environnements et pas uniquement ceux de production.
La fonction de production qui nécessite le plus de changement dans les habitudes sera sans contexte l’incident management, d’autant plus si cela s’accompagne d’un passage en micro-services avec le PaaS. Les ingénieurs supports peuvent passer d’une centaine de serveurs généralement Windows ou Unix, sur lesquels ils avaient des droits systèmes complets à devoir intervenir sur un service qui tourne sur des pods gérés de façon automatique par Kubernetes ou une technologie équivalente. Les réflexes de connexions, de logs systèmes, de parcourir des fichiers de logs applicatifs deviennent complètement caduques. Il faut au contraire monter en expertise à la fois sur la technologie utilisée, mais aussi avoir une bien meilleure compréhension de l’application. On peut avoir beaucoup d’information d’aide au débogage dans le Cloud, mais paradoxalement il peut être compliqué de s’y retrouver, le stockage coûtant extrêmement cher, il faut en permanence choisir ce qu’on souhaite conserver comme trace et leurs durées de rétention. Ceci représente un réel effort quand on avait l’habitude jusque-là de ne pas réellement se préoccuper du coût du stockage.
Tout ceci milite fortement pour une évolution du rôle traditionnel d’ingénieur support vers le métier de SRE ou APS, en s’appuyant sur des pratiques Devops car la frontière disparait fortement entre les deux mondes : le développeur et le support travaillant de concert, chacun apportant son expertise pour améliorer la qualité des services.
Alerting et gestion des incidents, mise en place de Trust & Control, accompagnement des pratiques de production impactées par le Cloud… Camille s’interroge sur son organisation opérationnelle actuelle.
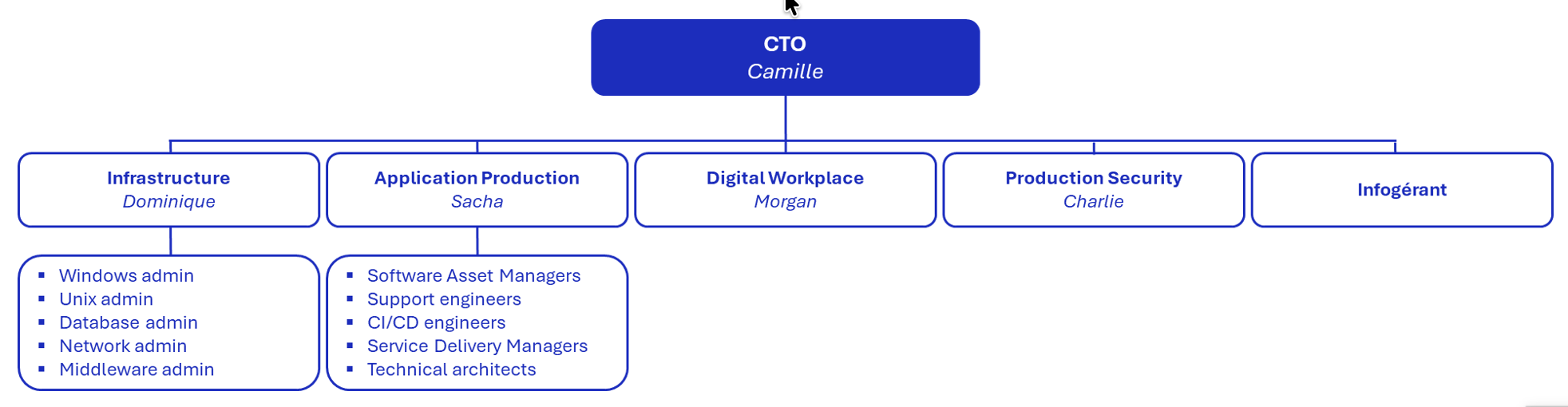
Principalement pour des raisons budgétaires et de contrôle du risque, Camille a fait le choix de conserver le provisionning des éléments. La migration du SI impliquera à la fois de migrer des applications en IaaS et d’autres en PaaS. Camille souhaite également que le support applicatif soit renforcé avec un rôle APS, évolution de l’équipe des support engineers, en charge de la gestion des incidents de bout-en-bout, devenu encore plus critique maintenant que l’infogérant n’est plus là pour apporter une couverture H24.

Le choix a donc été fait de faire évoluer l’entité Infrastructure vers une entité SRE (Site Reliability Engineering) dont le rôle est d’apporter l’expertise Infrastructure et les fonctionnalités du Cloud aux entités de développement. L’entité Application Production évolue vers un organe d’accompagnement et de supervision des activités de production. Cette équipe désormais nommée Run Control Tower a pour mission de définir et de piloter l’intégralité des activités de production, elle est également en charge de la gestion de crise. Enfin l’entité Application Production Support est créé afin de gérer opérationnellement et au quotidien les activités de production : incidents, requêtes, problèmes, changes...
A travers cet article nous avons effleuré pourquoi migrer tout ou partie d’un SI dans un environnement Cloud est une transformation d’envergure. Composante fondamentale du SI la production est évidemment impactée, d’autant plus quand cette transformation s’accompagne d’une refonte des applications vers du PaaS. Elle fait évoluer les missions du département de Production, historiquement plutôt infrastructure et technique, vers un rôle d’expert des services Cloud, d’accompagnement des équipes de développement, de garant des pratiques de production et de son pilotage.










