La matrice de priorité ITIL classique repose sur des jugements subjectifs en pleine crise ; une approche scorée et objective résout ce problème.

La gestion des incidents IT dispose d’un outil de référence pour décider comment réagir : la matrice de priorité, issue du cadre ITIL. Sa promesse ? Donner à chaque incident une priorité claire, et donc une réponse proportionnée. Mais dans la pratique, cette matrice repose sur des jugements humains formulés au pire moment : quand la pression est à son comble et le recul minimal. Le résultat : des priorités incohérentes, des équipes en tension permanente, et une qualité de données post-incident inexploitable. Je vous propose des pistes pour en proposer une implémentation rigoureuse, automatisée et consistante pour améliorer à la fois la prise en charge des incidents, mais aussi le pilotage de la qualité de service.
Dans le cadre ITIL classique, la priorité d’un incident est le produit de deux dimensions :
1. L’impact : dans quelle mesure l’incident affecte-t-il le business ? On parle généralement d’une échelle allant de « faible » à « élevée ». Parfois l’impact n’est même évalué que vis-à-vis du SI et pas du métier.
2. L’urgence : à quelle vitesse faut-il résoudre cet incident pour limiter les dégâts ? Une échelle similaire, de « faible » à « élevée » doit être renseignée par l’ingénieur de production.
La combinaison des deux dimensions donne une priorité, généralement de P1 à P4, qui détermine les SLA de traitement, le niveau d’escalade, et la mobilisation des équipes. Sur le papier, c’est séduisant. Dans la réalité opérationnelle, c’est une autre histoire.
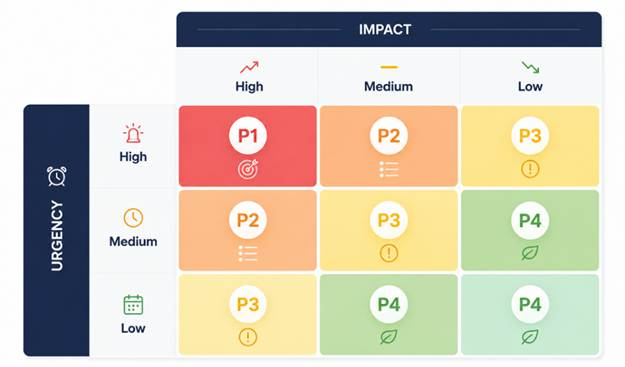
L’opérateur qui ouvre un ticket d’incident doit qualifier à la fois l’impact et l’urgence en faible, modéré ou élevé. Trois problèmes majeurs se posent immédiatement.
1. Chacun tend à surestimer les impacts qu’il connaît et à sous-estimer ceux qu’il ne maîtrise pas. Un impact fort sur le plan juridique sera minimisé par une équipe technique. Un impact financier marginal sera dramatisé par un opérateur sous pression.
2. L’urgence dépend fondamentalement de l’endroit d’où on la regarde. Pour l’IT, un service qui répond « lentement » peut paraître acceptable. Pour le métier en pleine journée de trading, toute latence est une catastrophe.
3. Au sein d’une même équipe, deux personnes ne placeront pas le curseur au même endroit sur une échelle de « pas urgent » à « très urgent ». Pire, une même personne peut avoir une évaluation différente de la même situation à quelques jours d’intervalle. Ce sont des jugements de valeur, pas des constats factuels. Les fonder sur une échelle générique garantit l’incohérence.
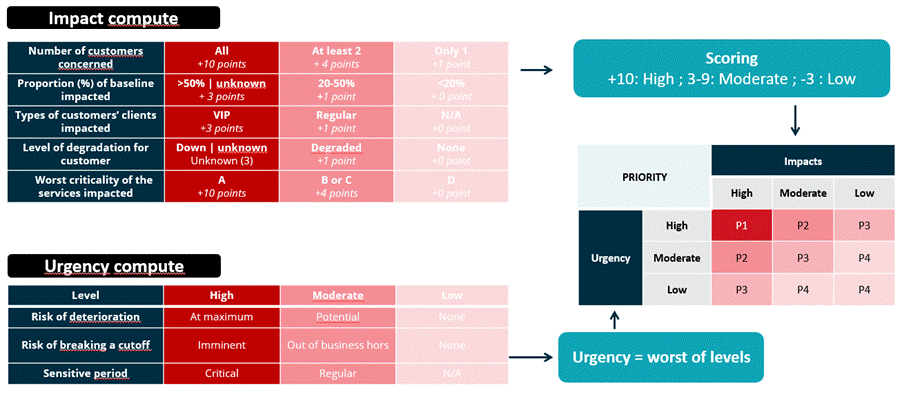
Le principe : définir des paramètres objectifs, leur associer des seuils, et calculer mécaniquement un score d’impact d’un côté, un score d’urgence de l’autre pour aboutir à une priorité factuelle, sans biais. Si vous avez mis en place des Business SLA, les valeurs associées à chaque critère sont des SLI [Google]. On conserve les deux dimensions d’impact et d’urgence que l’on quantifie grâce aux critères suivants.
1. La criticité des services concernés. Chaque service possède une criticité intrinsèque définie et revue régulièrement qui est positionnée en fonction des impacts financiers, juridiques, de qualité de service et d’image en cas de disfonctionnement.
2. Le nombre d’utilisateurs concernés. Un incident touchant un seul client ne se traite pas comme un incident systémique. Les seuils peuvent varier grandement selon que vous soyez sur une activité BtoB ou BtoC, un SaaS provider ou une application interne utilisée par une petite équipe.
3. Le type d’utilisateurs concernés. Les utilisateurs sont-ils internes ou externes, VIP, des client historiques ou nouveaux ?
4. La proportion de l’activité impactée. Toute l’activité est-elle impactée par l’incident ? Seulement une partie ? On est sur une activité temps réel ou de batchs ?
5. Le niveau de dégradation subit par les utilisateurs. Le service est-il complètement à l’’arrêt ? En mode dégradé ? Sans impact visible ?
6. Le risque de détérioration. Existe-t-il un risque d’effet domino technique, une saturation capacitaire, une corruption de données, un système de secours défaillant ?
7. Le risque de manquer un cut-off. Quelle est le risque de rater un batch de transfert financier, un reporting réglementaire, de ne pas respecter un SLA contractuel ?
8. La sensibilité de la période. Est-on en black Friday, en période de clôture comptable, d’une migration planifiée, lors d’une election à haut risque ?
Pour chaque critère, une valeur numérique est associée à chaque option. Il n’est pas toujours possible de connaitre la valeur d’un critère au moment de l’incident, dans ce cas le pire cas sera toujours considéré. Le score d’impact et le score d’urgence sont calculés indépendamment. Leur combinaison dans une matrice classique P1–P4 produit la priorité finale.
Cette approche peut sembler plus complexe que deux cases à cocher. Elle l’est. Mais cette élaboration est faite une fois, par les bonnes personnes, en amont et non par l’opérateur en plein stress d’un incident de production pour qu’il puisse se concentrer sur l’analyse et la mobilisation des ressources.
Le résultat est une priorité cohérente d’un incident à l’autre, exploitable dans les revues de qualité, et libérée des biais individuels. De plus elle reste compatible avec la matrice de priorité standard et une implémentation dans les outils ITSM du marché.
Ainsi, en pleine crise, les équipes ne débattent plus de ce qui est « urgent » ou « impactant ». Elles répondent à des questions factuelles : quel service est touché ? Combien de clients ? Y a-t-il un cut-off dans les deux heures ? Est-ce qu’on est en période de Black Friday ? La priorité s’en déduit mécaniquement. Idéalement, ces critères sont automatiquement évalués et renseignés en se basant sur la CMDB et la plateforme d’observabilité pour une étape de priorisation totalement automatique.
Avec une notion de priorité débarrassée de toute notion subjective, on peut désormais s’appuyer sur des fondations solides pour améliorer la gestion des incidents dans son ensemble.
La priorité se décide pendant l’incident, sur la base d’informations partielles et d’hypothèses. La sévérité se mesure après l’incident, une fois que l’ensemble des impacts réels peut être évalué.
Ce sont deux choses fondamentalement différentes, et les confondre génère des aberrations. Un incident P1 peut très bien se conclure en Sévérité 4 : un batch tombé quelques minutes avant un cut-off, mais rétabli à temps sans impact client. Un incident P4 peut aboutir en Sévérité 1 : une dégradation silencieuse passée sous les radars, qui a corrompu des données pendant 48 heures.
La popularité de de la notion de priorité a mené les responsables IT à l’utiliser comme seul baromètre de la stabilité de leur SI, ce qui n’est pas son rôle contrairement à la sévérité. La tendance à objectiver les équipes de production sur cet indicateur a conduit les équipes à minimiser la priorité des incidents, pour qu’ils ne soient pas visibles en vertu de la loi de Goodhart. Cette pression du nombre de P1/P2 mène aussi à des débats et affrontements entre les équipes qui ne veulent pas se retrouver assignés sur un incident de ce type.
Il est courant de voir des CMDBs organisées autour des applications, avec une criticité fixée une fois par an lors d’un comité. Problème : une application est toujours aussi critique que le service le plus critique qui l’utilise. Et ça change vite, sans que personne ne s’en aperçoive.
Un composant backend mutualisé, initialement jugé non critique, peut devenir le point central de dix services stratégiques au fil des mois. Plus une application est backend, partagée et facile d’accès, plus sa criticité réelle a tendance à croître avec le temps. Seule la criticité des services — stable, ancrée dans la réalité des usages métier — est un indicateur fiable.
Il est tentant de définir des taux de disponibilité pour chaque service, et d’en déduire des niveaux de réactivité. C’est une simplification trompeuse.
La disponibilité est un indicateur binaire : le service répond ou ne répond pas, en partie ou en totalité. Elle ne capture ni la latence, ni le volume traité, ni la fréquence des transactions, ni la justesse des données retournées. Un service techniquement « disponible » à 99,9 % peut offrir une expérience désastreuse si ses temps de réponse ont triplé. Un bureau de poste ouvert avec cinquante personnes dans la file est-il vraiment disponible ? Réserver la notion de disponibilité aux obligations contractuelles est raisonnable. En faire le fondement de votre système de priorité, c’est se priver de tout ce qui compte vraiment.
Un patient qui attend aux urgences depuis dix heures pour un état grippal ne passe pas devant un patient arrivé il y a vingt minutes pour une fracture ouverte. Le temps d’attente ne change pas la nature du problème.
Pourtant, dans de nombreuses organisations, la pression monte au fur et à mesure qu’un incident « traîne », et les équipes sont tentées d’escalader la priorité uniquement pour débloquer de l’attention. Ce qui doit faire évoluer la priorité, c’est l’évolution des critères : si une proportion croissante d’activité est touchée, si un cut-off approche, si un risque d’effet domino devient imminent — alors oui, la situation doit être réévaluée. Pas parce que l’incident dure depuis longtemps.
Une matrice de priorité bien construite ne doit pas être un formulaire rempli à la va-vite. C’est un système expert codé en amont, qui rend service au moment où l’équipe en a le plus besoin : quand tout va mal, vite, et que la moindre hésitation ou erreur de jugement peut couter cher.
Après la crise, les données accumulées sont homogènes et fiables. Les post-mortems gagnent en pertinence. Les tendances deviennent lisibles. L’amélioration continue devient possible à la fois coté IT mais aussi coté Métier.
Et quand vous serez prêt, vous pourrez abandonner la notion de priorité, ne raisonner que par score sur les signaux faibles detectés par votre plateforme d’observabilité et gérer les vibrations du système, automatiquement, avant que cela ne devienne un incident.
Si ce sujet vous intéresse et que vous souhaitez prolonger la discussion, n’hésitez pas à me contacter !










